Параметризованный декоратор: корова мычит, а кошка мяукает, несмотря на то, что обе - животные.
Генератор с условием выхода из бесконечного цикла. Можно посылать сигнал!
понедельник, августа 30
пятница, августа 20
Обход прошитого дерева
Элемент бинарного дерева содержит две ссылки: на левое и правое поддерево. Чтобы обойти обычное бинарное дерево требуется алгоритм, использующий стек, т.к. нижележащие деревья не содержат информации о своих предках. Поэтому, чтобы вернуться в узел, в котором возможно ветвление, мы помещаем его в стек. Если же процедура обхода не находит следующего элемента, то мы берем его из стека и повторяем её.
Учитывая то, что многие узлы могут иметь одну из ссылок незанятыми, можно прийти к выводу, что дерево можно представить более эффективно в памяти и сделать обход его более быстрым.
А. Дж. Перлис и Ч. Торнтон предложили использовать эти незанятые ссылки в качестве "нитей", которые связаны с остальными частями дерева. Дерево с такими связями называют "прошитым бинарным деревом".
Чтобы отличать нити от обычных ссылок используются два бита, характеризующие тип связи. Для определенности, если бит RS = 0, то правая связь обычная, если RS = 1, то это связь типа "нить". Аналогично для бита LS. В памяти оба бита естественно представимы в виде одного слова.
Для удобных реализаций алгоритма обхода прошитого дерева вводится ограничение на дерево:
Реализация на Питоне (в виде пакета) включает в себя
Учитывая то, что многие узлы могут иметь одну из ссылок незанятыми, можно прийти к выводу, что дерево можно представить более эффективно в памяти и сделать обход его более быстрым.
А. Дж. Перлис и Ч. Торнтон предложили использовать эти незанятые ссылки в качестве "нитей", которые связаны с остальными частями дерева. Дерево с такими связями называют "прошитым бинарным деревом".
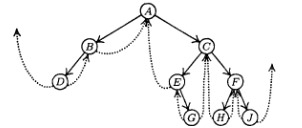 |
| Прошитое дерево. Из книги Кнут Д. "Искусство программирования." |
Для удобных реализаций алгоритма обхода прошитого дерева вводится ограничение на дерево:
- корневой элемент имеет правую ссылку на само себя,
- построение дерево начинается только влево от корня.
 | ||
| Пример организации прошитого дерева с учетом всех ограничений. |
- Дерево,
- генератор произвольного дерева,
- алгоритм обхода,
- алгоритм вставки одного произвольного элемента в произвольную часть дерева (либо в середину, либо в качестве продолжения дерева),
- пробную программу с генерацией дерева автоматически и вручную.
- А так же, весьма вероятно, ненужный вам проект для Eclipse.
среда, августа 18
Обход бинарного дерева
Определение: бинарное дерево это множество, которое либо пусто, либо состоит из корневого элемента и двух бинарных деревьев: левого и правого.
Это определение рекурсивно. Оно отличается от определения обычного дерева возможностью существования "пустого" бинарного дерева.
Типичны задачи обхода этого дерева. Стандартных алгоритмов обхода три.
Прямой алгоритм обхода бинарного дерева
Реализация на Java бинарного дерева, а так же прямого и центрированного алгоритма обходов, доступна для скачивания. Кстати, мое бинарное дерево использует обобщения (generics) для контейнера данных. А вот алгоритмы обхода реализованы только для Integer.
Это определение рекурсивно. Оно отличается от определения обычного дерева возможностью существования "пустого" бинарного дерева.
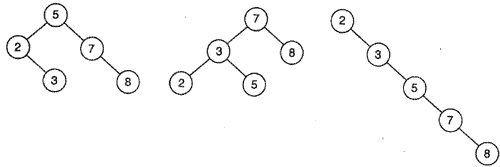 |
| Разные двоичные деревья. |
Прямой алгоритм обхода бинарного дерева
- Зайти в левое дерево,
- зайти в корень,
- зайти в правое дерево.
- Зайти в корень,
- зайти в левое дерево,
- зайти в правое.
- Зайти в левое дерево,
- зайти в правое дерево,
- зайти в корень.
Реализация на Java бинарного дерева, а так же прямого и центрированного алгоритма обходов, доступна для скачивания. Кстати, мое бинарное дерево использует обобщения (generics) для контейнера данных. А вот алгоритмы обхода реализованы только для Integer.
вторник, августа 17
Осевое преобразование
 |
| Картинка по запросу "pivot step" |
Осевое преобразование матрицы - очень простое. Пусть дана матрица A
$A = \left( \begin{array}{ccccc} \ldots & \ldots & \ldots & \ldots & \ldots \\ \ldots & a & \ldots & b & \ldots \\ \ldots & \ldots & \ldots & \ldots & \ldots \\ \ldots & c & \ldots & d & \ldots \end{array} \right)$
Операция осевого преобразования c осевым элементом a (англ. pivot step) превращает её в следующую матрицу A1
$A_1 = \left( \begin{array}{ccccc} \ldots & \ldots & \ldots & \ldots & \ldots \\ \ldots & 1/a & \ldots & b/a & \ldots \\ \ldots & \ldots & \ldots & \ldots & \ldots \\ \ldots & - \frac{c}{a} & \ldots & d - \frac{bc}{a} & \ldots \end{array} \right)$
Строка и столбец матрицы, на которых расположен элемент a называются осевыми строкой и столбцом.
Пошаговое осевое преобразование по главной диагонали используется для получения матрицы идентичности. Это нужно, например, для вычисления обратной матрицы.
В случае больших разреженных матриц имеет смысл задавать матрицу в виде двусвязанных ортогональных списков. Моя реализация алгоритма осевого преобразования на Java работает с матрицами такого вида из предыдущего поста. Мне понравился алгоритм вставки элементов в произвольное место такой матрицы. Он получился красивым, черт возьми. Там ведь по сути идет работа с двумя замкнутыми кольцами из односвязных элементов, в котором мы по определенному правилу меняем связи.
Весь проект для Eclipse (матрица, генератор матриц, алгоритм) можно скачать в ZIP архиве.
пятница, августа 13
Разреженная матрица
Матрица называется разреженной, если в ней относительно много нулей и довольно мало значений. Ниже пример разреженной матрицы.
$\left( \begin{array}{ccccc} 1 & 2 & 1 & 0 & 1 \\ 0 & 0 & 1 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 3 \end{array} \right)$
Разреженной матрицей удобно описывать рельеф местности. Понятно что хранить в памяти всю матрицу неэффективно. Хорошо бы оставить только "полезные значения", то есть, ненулевые. В книге Кнута "Искусство программирования" приводится пример организации матрицы в виде двусвязанных списков.
Двусвязанный список состоит
Реализация разреженной матрицы на Java. Я еще не тестировал её, т.к. она лишь часть алгоритма для осевого преобразования.
Элементами матрицы являются экземпляры класса MNode - и это всего лишь те самые двусвязанные списки
$\left( \begin{array}{ccccc} 1 & 2 & 1 & 0 & 1 \\ 0 & 0 & 1 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1 & 3 \end{array} \right)$
Разреженной матрицей удобно описывать рельеф местности. Понятно что хранить в памяти всю матрицу неэффективно. Хорошо бы оставить только "полезные значения", то есть, ненулевые. В книге Кнута "Искусство программирования" приводится пример организации матрицы в виде двусвязанных списков.
Двусвязанный список состоит
- из двух ссылок: на левый и верхний элемент,
- номера столбца и номера строки
- хранимого значения (например, высоты участка с соответствующими координатами)
Реализация разреженной матрицы на Java. Я еще не тестировал её, т.к. она лишь часть алгоритма для осевого преобразования.
Элементами матрицы являются экземпляры класса MNode - и это всего лишь те самые двусвязанные списки
четверг, августа 5
Основные характеристики дискретной случайной величины
Математическое ожидание ДСВ: $A = \sum\limits_{k} A_k * p_k$
Дисперсия D случайной величины вычисляется как математическое ожидание величины $(A-An)^2$, поэтому
$D = \sum\limits_{k}(k-An)^2p_k$
Среднеквадратическое отклонение $\delta = \sqrt{D}$. Смысл этой величины такой: случайная величина принимает значение не из промежутка $[A-r\delta,A+r\delta]$ с вероятностью не превышающей $1/r^2$. Например, событие $|A-An| > 2\delta$ происходит с вероятностью не больше $1/4$
Дисперсия D случайной величины вычисляется как математическое ожидание величины $(A-An)^2$, поэтому
$D = \sum\limits_{k}(k-An)^2p_k$
Среднеквадратическое отклонение $\delta = \sqrt{D}$. Смысл этой величины такой: случайная величина принимает значение не из промежутка $[A-r\delta,A+r\delta]$ с вероятностью не превышающей $1/r^2$. Например, событие $|A-An| > 2\delta$ происходит с вероятностью не больше $1/4$
среда, августа 4
Приближенное вычисление факториала
В 1730 году Джеймс Стирлинг в своей работе привел формулу приближенного вычисления факториала
$n! \approx \sqrt{2\pi n}*(\frac{n}{e})^n$
Она дает погрешность $\frac{1}{12n}$
Погрешность измерений $\delta x(n)$ это величина характеризующая отклонение приближенного значения от истинного. Т.е. $|I \index n - F\index n| \leq \delta x(n)$
$n! \approx \sqrt{2\pi n}*(\frac{n}{e})^n$
Она дает погрешность $\frac{1}{12n}$
Погрешность измерений $\delta x(n)$ это величина характеризующая отклонение приближенного значения от истинного. Т.е. $|I \index n - F\index n| \leq \delta x(n)$
вторник, августа 3
Подписаться на:
Комментарии (Atom)